История подходов к проектированию ИС
Начнем с банальности: в каждой информационной системе используются базы данных. Дополним это утверждение тем, что лидерами рынка здесь являются Oracle, IBM DB2 и MS SQL. На основе этих СУБД построены информационные системы различных классов и масштабов. При этом разработчики многих современных проектов испытывают ограничения, связанные с использованием традиционных табличных реляционных СУБД и пытаются найти им альтернативу. Но не будем торопиться и пробежимся для начала по основным историческим этапам классического подхода.
О моделях данных
СУБД характеризуются, прежде всего, моделью данных. Тем, в каком виде хранятся данные в БД, как с ними происходит работа, и как обеспечивается их целостность. Реляционные СУБД, которых сейчас подавляющие большинство, работают с реляционной моделью: данные хранятся в виде таблиц, связанных отношениями. Иерархическая модель характеризуется древовидной структурой данных — объекты находятся на разных уровнях и связаны отношениями «родитель-потомок». Сетевая модель является развитием иерархической, ключевое ее отличие — объект-потомок может иметь более одного предка.
Самое начало
Первой СУБД в истории считается IBM IMS, разработанная в конце 1960-х годов. Система, использующая иерархическую модель данных, продолжает развиваться, и в 2017 году вышла очередная версия. В семидесятых годах началась разработка СУБД с реляционной моделью данных, и к концу восьмидесятых они стали занимать доминирующее положение. При наличии ряда преимуществ у иерархической модели, реляционная решила очень важную на тот момент задачу: как компактно упаковать данные, и как их извлекать без распаковки большого объема. Особенно важно это было для персональных компьютеров, ведь тот же IBM PC, к примеру, работал с дискетами объемом до 360 КБайт.

С развитием СУБД и увеличением сложности информационных систем возникла необходимость в унификации средств работы с данными, и в 1986 году был принят первый стандарт SQL — языка, разработанного для взаимодействия с реляционными СУБД. Отметим, что это был не единственный вариант — так, в Университете Беркли была создана реляционная СУБД Ingres, дальний прародитель современной PostgreSQL. Она использовала язык QUEL, который не выдержал конкуренции с SQL.
Разработчики информационных систем получили мощное орудие — СУБД с языком запросов SQL. Не нужно самостоятельно решать задачи хранения, модификации и поиска информации. Да и вообще, во многих случаях разработчику даже не нужно знать, с какой СУБД он работает.
Удобные и неудобные таблицы
Еще одна банальность: информационные системы создаются для различных предметных областей. В одних табличное представление данных будет удобно, а реляционные отношения согласуются с логикой работы. В других решение о том, как связать СУБД и приложение окажется неоднозначным. Здесь стоит обратить внимание на понятие информационной модели — формального описания того, что происходит в предметной области информационной системы. Представлена она обычно в виде диаграмм «сущность-связь». Разработчику на основе информационной модели необходимо решить, как будет осуществляться работа с данными в приложении, как будут представлены сущности и связи. А потом — реализовать связь с табличной моделью данных СУБД.
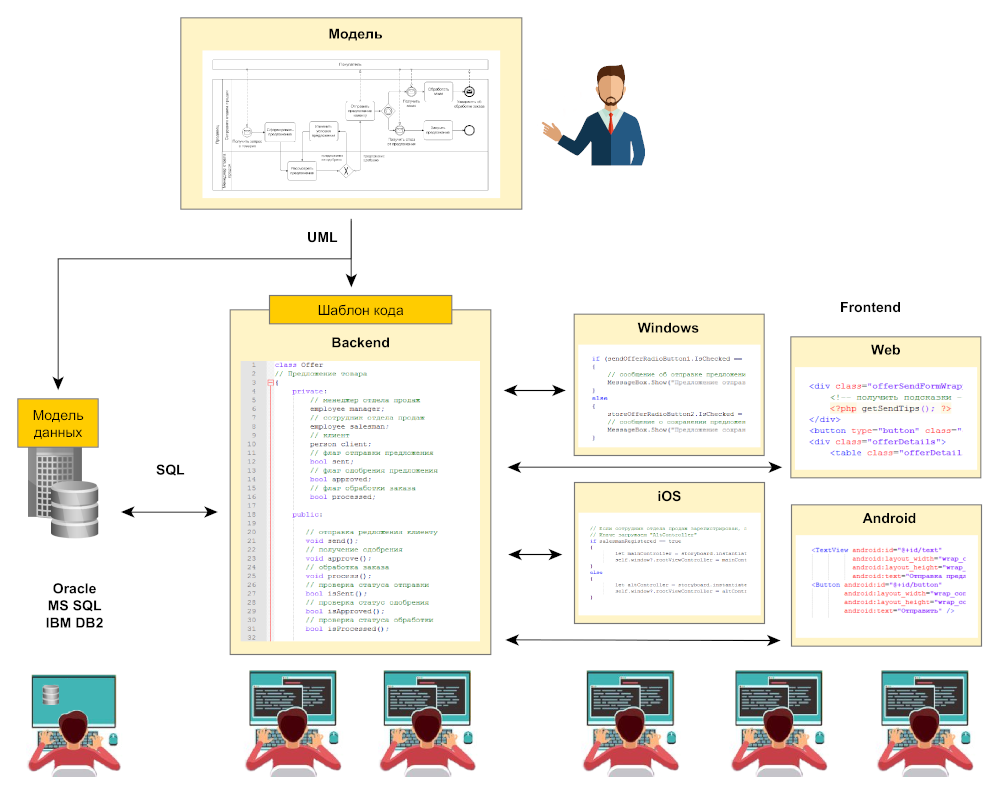
При создании информационных систем используются различные средства и методологии для моделирования. Эти модели могут быть использованы непосредственно при проектировании. К примеру, на основе описания на языке UML можно автоматизированно создать модель данных и сгенерировать шаблоны программного кода.
Виртуальная объектная БД
Когда программный код информационной системы построен в соответствии с объектно-ориентированной парадигмой, логичным является желание работать с СУБД с помощью методов объекта. В идеале — разработчик не должен вообще касаться как модели данных, так и связи объектов приложения с ней. Так появляется ORM — Object-Relational Mapping, объектно-реляционное отображение.
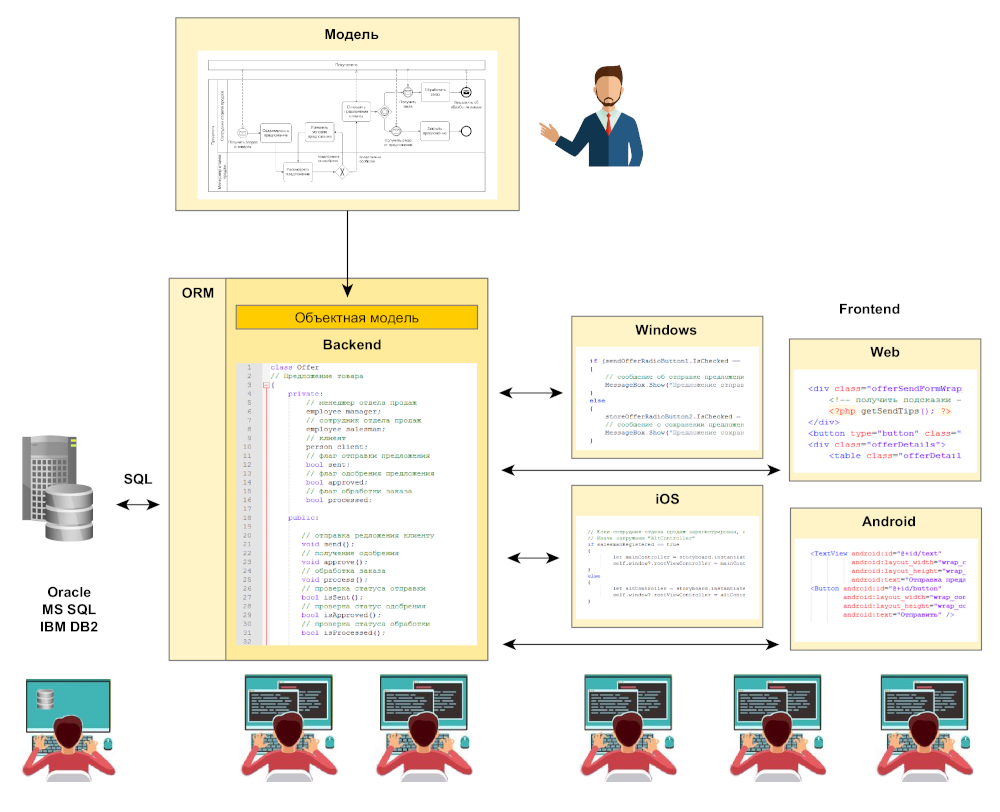
Для разработчика не имеет значения, какая СУБД находится в основе системы, он не использует в коде язык запросов. Разработка программного продукта начинается с информационной модели и переходит к реализации объектной модели с помощью программного кода бэкенда. А ORM на основе этой модели принимает решение о формировании таблиц и отношений в «настоящей» БД и в дальнейшем поддерживает связь. Эффективно с точки зрения скорости и удобства разработки, но головной боли тоже прибавляется, в частности, от высокой требовательности ORM к вычислительным ресурсам по причине значительной избыточности автоматически генерируемых запросов.
К тому же, при изменении структуры данных в коде бэкенда ORM будет их транслировать в модель данных, с немалой вероятностью это выльется в нарушение целостности существующей базы и потерю информации.
Ускорение и дробление
Хорошо, теперь нужно искать способ радикального ускорения работы получившейся конструкции без разрушения основания. Например, такой вариант: берем и прикручиваем к существующей реляционной БД систему, работающую в памяти, такую как Apache Ignite. Нужно еще больше ресурсов, но цель в какой-то степени достигнута, с in-memory data grid работа происходит быстро.
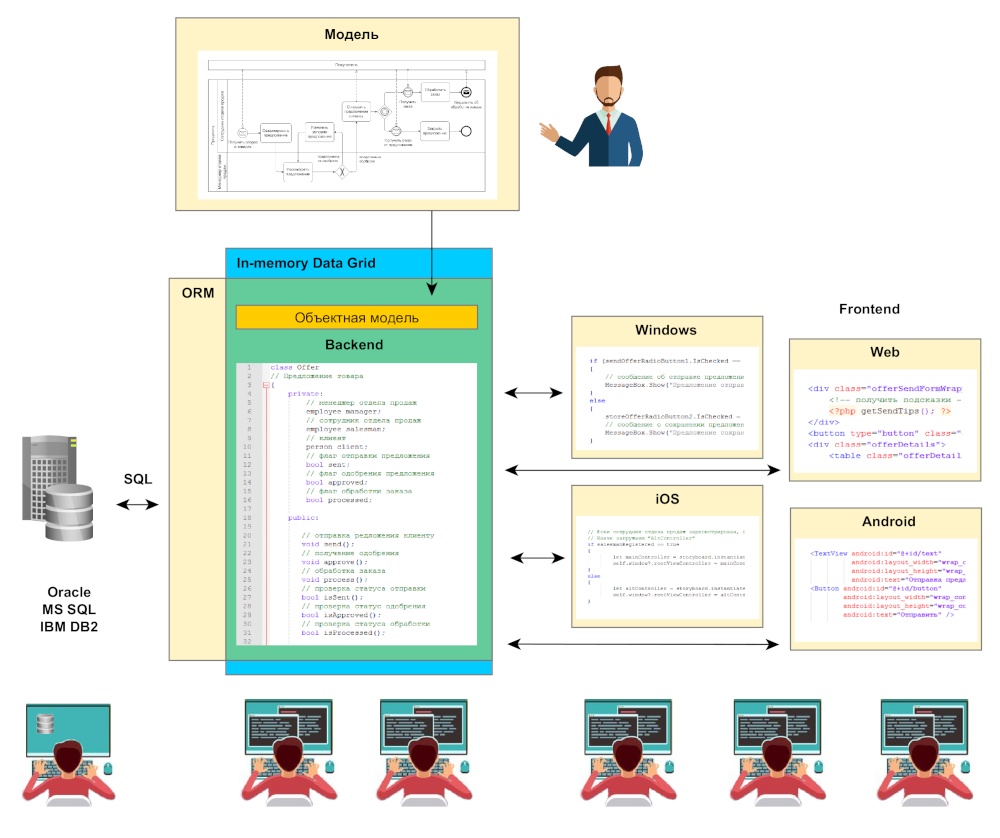
Увеличение масштаба системы, количества данных и кода приводит к следующей проблеме — в какой-то момент оказывается, что нужно объять необъятное, рассматривая систему как единое целое, и координировать буквально армию разработчиков. Чем крупнее и сложнее система, тем больше оказываются затраты на ее модернизацию, вплоть до того, что целесообразнее оказывается разработка новой системы вместо совершенствования старой.
Чтобы увеличить гибкость системы и сделать возможной модернизацию отдельных ее частей без вмешательства в функционирование остальных, ее приходится дробить до настолько малых единиц, что с каждой из них будет справляться небольшая команда.
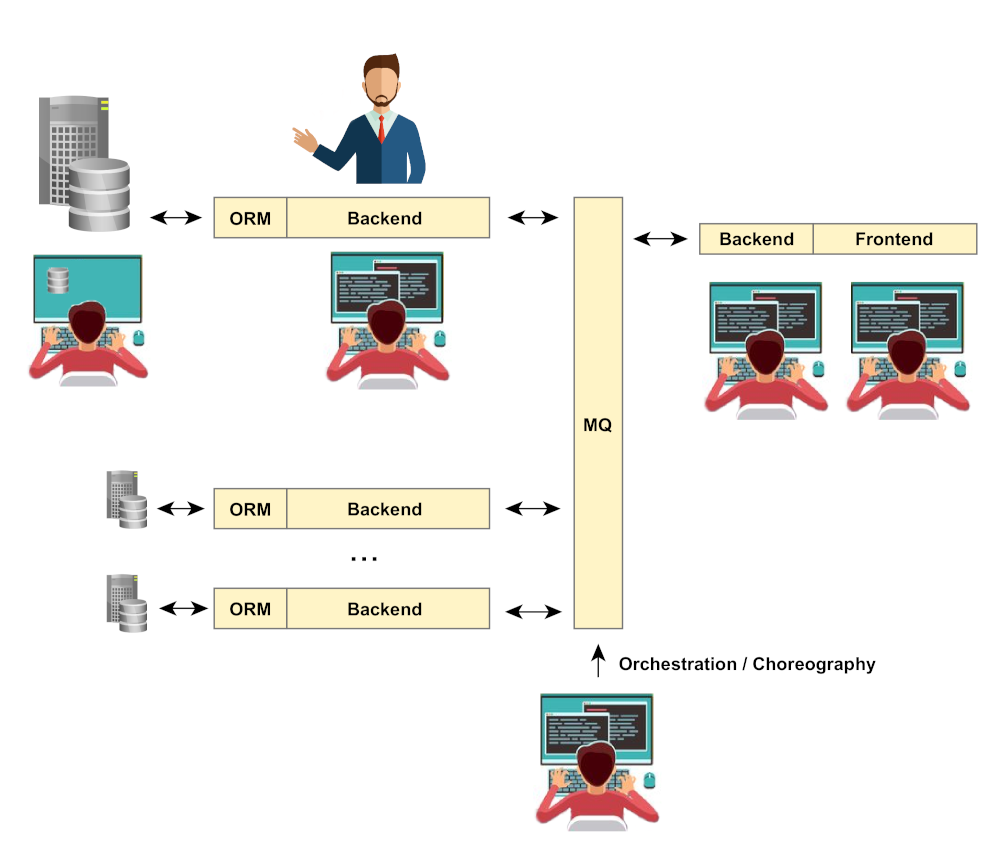
Оркестровка и танцы
И, наконец, еще один важный момент, возникающий при работе с микросервисной системой. Необходима формализация — упорядочивание взаимодействия сервисов, которое будет происходить не только по внешнему указанию, но и автономно. Для решения задачи выделяют два подхода — Service Orchestration и Service Choreography.
Не вдаваясь в детали:
- Orchestration — централизованный, оперирует взаимосвязями сервисов с точки зрения одного управляющего.
- Choreography — децентрализованный, глобальное описание взаимосвязей без выделения центра.
Дальнейшее погружение в объекты
Развитие информационных систем привело к тому, что в реляционных СУБД данные хранятся в виде таблиц, в то время как информационная модель остается объектной; бэкенд разрабатывается на объектно-ориентированных языках, и микросервисы тоже начинают напоминать объекты. Вот эта идея достойна дальнейшего развития.
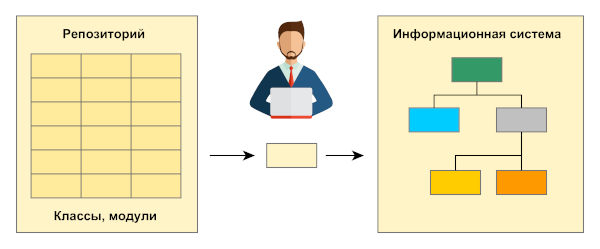
Для реализации нового подхода, не основанного на описанных ранее вариантах, приходится отказываться от реляционной СУБД. При этом целесообразным оказалось возвращение к истокам — к иерархической модели. Так мы смогли не просто избавиться от промежуточных звеньев в цепочке между кодом и данными, стало возможным переработать сам принцип хранения и обработки. Отказавшись от реляционной БД и ресурсоемкого ORM, мы получили значительный выигрыш в производительности ценой компактности хранения.
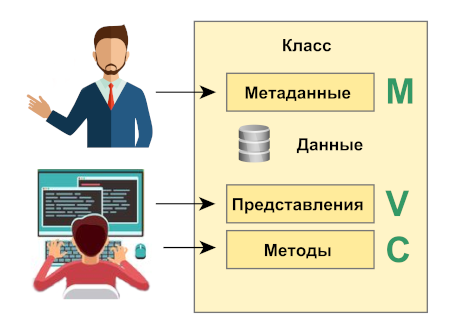
Вводим понятие класса — элементарной единицы структуры информационной системы. Хранение данных производится в объектах класса, и для доступа к ним будут использоваться его методы в соответствии с принципом инкапсуляции. Каждый класс предназначен для реализации какого-либо простого функционала. Любая сложная система должна собираться из таких классов как из кирпичиков «Лего».
Что касается наследования. Есть класс, реализующий общую функциональность. Нужно его немного доработать, добавив пару методов. Родительский класс не трогаем, а создаем дочерний, в нем дописываем программный код. Теперь дочерний класс может применяться по назначению в соответствии с измененной логикой, а работать с получаемым им данными можно с помощью методов родительского.
Этот же подход используется при модернизации системы: не отказываясь от работающего в данный момент класса, создается дочерний, в котором переопределяются методы родительского.
Уменьшение количества кода
Постоянное повторное использование ранее созданных классов способствует уменьшению количества кода, который необходимо написать при разработке системы. Но есть возможность еще более значительного сокращения — для этого нужно описывать сами классы не программным кодом, а с помощью метаданных. Для этого вполне подойдет XML. В реализации методов класса код все-таки нужен, но при таком подходе он будет физически отделен от метаданных.
Получается следующее: класс представляет собой папку, в которой лежат файлы с метаданными и программным кодом. Также здесь присутствует его визуальное представление в виде HTML и/или JS. Таким образом мы и получаем функционально законченную сущность, реализующую схему Model-View-Controller, MVC.
В том случае, если при разработке информационной системы уже существуют все классы с необходимой элементарной функциональностью (компоненты или так называемые «кирпичики Lego»), написание нового программного кода не потребуется в принципе.
Минимизация непосредственно программирования решает еще одну проблему — при разработке системы программисту приходится разбираться в предметной области, в задачах, решаемых с помощью создаваемого продукта. Если бы в процессе участвовал специалист в данной области, то можно было бы значительно сократить сроки как разработки, так и тестирования. Но такие специалисты, как правило, не являются программистами.
В то же время при описании классов в виде метаданных уже можно использовать визуальные средства редактирования, радикально снижающие порог вхождения для не-программиста.
Эволюция и инерция
Существующие сегодня информационные системы находятся на разных этапах развития. Но большинство, как отмечалось в начале, базируются на морально устаревших реляционных СУБД. И именно эти СУБД тормозят их эволюцию, а повсеместное распространение обусловлено огромной инерцией индустрии. Информационные системы, с увеличением масштабов, становятся все более требовательны к количеству машинных и человеческих ресурсов для стабильной работы и развития. Дробление системы, когда ее уже невозможно рассматривать как монолитную — приемлемое решение. Однако, эта «Пиррова победа» была бы не нужна, в случае если систему изначально проектировали как композиционную и состоящую из элементарных модулей. Подход с развитым наследованием и многократным повторным использованием модулей позволяет строить сложные системы постепенно, обладая сравнительно небольшими ресурсами.

